


はじめに
- AgentKit とは?
TypeScript 製のエージェント開発フレームワークで、以下を特徴とします。- 決定論的ルーティング
入力内容や意図に応じて、あらかじめ定義したルールで必ず同じ経路を通す仕組み。 - マルチプロバイダー対応
OpenAI、Anthropic、Azure など、複数の大規模言語モデル(LLM)サービスを差し替え可能。 - MCP(Model-Agent Communication Protocol)採用
プロンプトやツール呼び出しを標準化するプロトコルで、外部ツールやプラグインとの連携を簡単に。 - TypeScript コミュニティとの親和性
型定義やエコシステム(npm/GitHub)を活用し、既存の開発ツールとスムーズに統合。
- 決定論的ルーティング
- Inngest Dev Server との統合
- ローカル開発環境
Dev Server を立ち上げるだけで、クラウドにデプロイする前のイベント駆動ワークフローを手元でシミュレーション可能。 - オーケストレーションエンジン
本番環境では Inngest がイベント処理をクラウド上で管理し、失敗時の自動リトライやスケーラビリティを提供。 - 耐障害性(フォールトトレランス)
処理中のエラーを検知して再実行、あるいは補償トランザクションを挟むことで、ミッションクリティカルなフローも安全に運用。
- ローカル開発環境
このように、AgentKit+Inngest で、TypeScript ベースの AI エージェントを「ローカルで素早く試作 → クラウドで堅牢に運用」まで一気通貫でサポートします。
ソースコードはこちら
ドキュメントはこちら
INNGESTの利用例
以下のような企業・サービスが Inngest を採用しています。
- Ocoya
ソーシャルメディア&eコマースワークフローを Inngest 上で構築し、開発速度とデバッグ効率を大幅に向上させています。Pepsi や WPP など大手企業も利用するプラットフォームです (inngest.com)。 - Otto
マルチテナント対応の高度な同時実行制御を必要とする AI プラットフォームで、ドキュメントやウェブ情報を即時に分析・変換するワークフローを Inngest で実現しています (inngest.com)。 - Resend
ドメイン検証フローなどバッチ処理を数日で実装し、継続的な新機能開発を高速化。数千–数百万のデベロッパー利用を見据えたスケーラビリティを担保しています (inngest.com)。 - SoundCloud, TripAdvisor, Resend, Contentful, BrowserStack, GitBook などのプロダクトチームが、AI ワークフローやサーバーレス処理の信頼性向上のために Inngest を活用しています (inngest.com)。
- オープンソース導入例としては、observerly, You Got Bud, Roev といった企業が StackShare 上で Inngest をテックスタックに挙げています (stackshare.io)。
試してみる
準備
quick-startコードのダウンロード
% mkdir quick-start
% cd quick-start
% npx git-ripper https://github.com/inngest/agent-kit/tree/main/examples/quick-start
% npm installhttps://claude.ai でAPIキーを取得し、.zshrc等に記述する
export ANTHROPIC_API_KEY=Index.tsサンプル
- dbaAgent
- createAgent関数によるエージェント生成
- name, descriptionはLLMがどのエージェントを呼ぶかを決定するために使用される
- systemは最初のプロンプトとして使用される
- modelとして、Anthropicのclaude-3-5-haiku-latestを指定している
- toolsで、エージェントが呼び出すtoolを指定している
- このprovider_answerというtoolがanswerを受け取った場合、network.state.data.dba_agent_answer にanswerを保存するという動作を定義している
- securityAgent
- devOpsNetwork
- 複数のエージェントを通信させるネットワークを生成する
- agents: このネットワークに参加する Agent のリスト。
- router: リクエストや状態に応じて、どの Agent に処理を回すかを決める関数。
- network.state.data.dba_agent_answer がまだ無ければ dbaAgent を呼ぶ
- DBA の回答があってセキュリティの回答が無ければ securityAgent を呼ぶ
- 両方の回答が揃っていれば何も返さず終了
- server
- agents: ここに単独で動かす Agent を個別追加できますが、今回は空配列。
- networks: 先ほど定義した devOpsNetwork を登録。
- ポート
3010で HTTP サーバーを立ち上げ、受信を開始。
import "dotenv/config";
import { anthropic, createAgent, createNetwork, createTool, Tool } from "@inngest/agent-kit";
import { createServer } from "@inngest/agent-kit/server";
import { z } from "zod";
export interface NetworkState {
// answer from the Database Administrator Agent
dba_agent_answer?: string;
// answer from the Security Expert Agent
security_agent_answer?: string;
}
const dbaAgent = createAgent({
name: "Database administrator",
description: "Provides expert support for managing PostgreSQL databases",
system:
"You are a PostgreSQL expert database administrator. " +
"You only provide answers to questions linked to Postgres database schema, indexes, extensions.",
model: anthropic({
model: "claude-3-5-haiku-latest",
defaultParameters: {
max_tokens: 4096,
},
}),
tools: [
createTool({
name: "provide_answer",
description: "Provide the answer to the questions",
parameters: z.object({
answer: z.string(),
}),
handler: async ({ answer }, { network }: Tool.Options<NetworkState>) => {
network.state.data.dba_agent_answer = answer;
},
}),
]
});
const securityAgent = createAgent({
name: "Database Security Expert",
description:
"Provides expert guidance on PostgreSQL security, access control, audit logging, and compliance best practices",
system:
"You are a PostgreSQL security expert. " +
"Provide answers to questions linked to PostgreSQL security topics such as encryption, access control, audit logging, and compliance best practices.",
model: anthropic({
model: "claude-3-5-haiku-latest",
defaultParameters: {
max_tokens: 4096,
},
}),
tools: [
createTool({
name: "provide_answer",
description: "Provide the answer to the questions",
parameters: z.object({
answer: z.string(),
}),
handler: async ({ answer }, { network }: Tool.Options<NetworkState>) => {
network.state.data.security_agent_answer = answer;
},
}),
]
});
const devOpsNetwork = createNetwork<NetworkState>({
name: "DevOps team",
agents: [dbaAgent, securityAgent],
router: async ({ network }) => {
if (network.state.data.dba_agent_answer && !network.state.data.security_agent_answer) {
return securityAgent;
} else if (network.state.data.security_agent_answer && network.state.data.dba_agent_answer) {
return;
}
return dbaAgent;
},
});
const server = createServer({
agents: [],
networks: [devOpsNetwork],
});
server.listen(3010, () => console.log("Agent kit running!"));AgentKit serverの起動
% npm run
> quick-start@1.0.0 start
> tsx --watch ./index.ts
Agent kit running!Inngest dev serverの起動
- ローカルの3010に起動したAPIサーバーをバックエンドとして使用する、ダッシュボードウェブアプリがポート8288に起動される。
% quick-start % npx inngest-cli@latest dev -u http://localhost:3010/api/inngest
Need to install the following packages:
inngest-cli@1.8.2
Ok to proceed? (y)
[09:47:38.109] INF service starting caller=devserver service=devserver
[09:47:38.109] INF service starting caller=executor service=executor
[09:47:38.109] INF service starting caller=api service=api
[09:47:38.109] INF starting server caller=api addr=0.0.0.0:8288
[09:47:38.109] INF subscribing to function queue
[09:47:38.109] INF starting event stream backend=redis
[09:47:38.109] INF service starting caller=runner service=runner
[09:47:38.109] INF autodiscovering locally hosted SDKs
[09:47:38.110] INF service starting caller=connect-gateway service=connect-gateway
[09:47:38.110] INF subscribing to events topic=events
[09:47:38.110] INF apps synced, disabling auto-discovery
Inngest Dev Server online at 0.0.0.0:8288, visible at the following URLs:
- http://127.0.0.1:8288 (http://localhost:8288)
- http://192.168.3.15:8288ダッシュボード
http://127.0.0.1:8288/ を開く
関数の呼び出し
- Functions > Invokeボタンをクリックする
- index.tsのネットワーク名が、関数名DevOps teamとして表示される
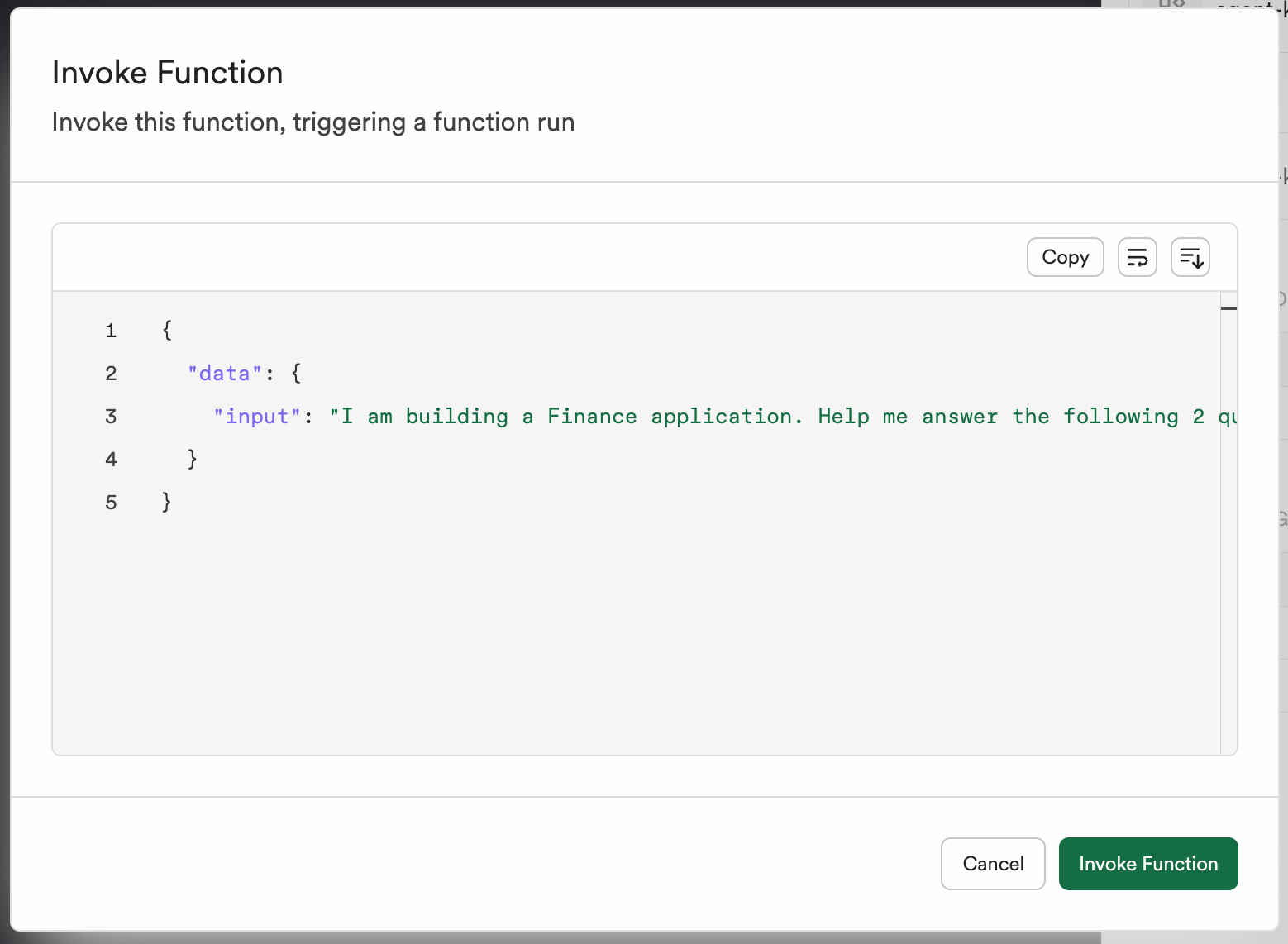
Input promptの送信
{
"data": {
"input": "I am building a Finance application. Help me answer the following 2 questions: \n - How can I scale my application to millions of request per second? \n - How should I design my schema to ensure the safety of each organization's data?"
}
}
実行結果
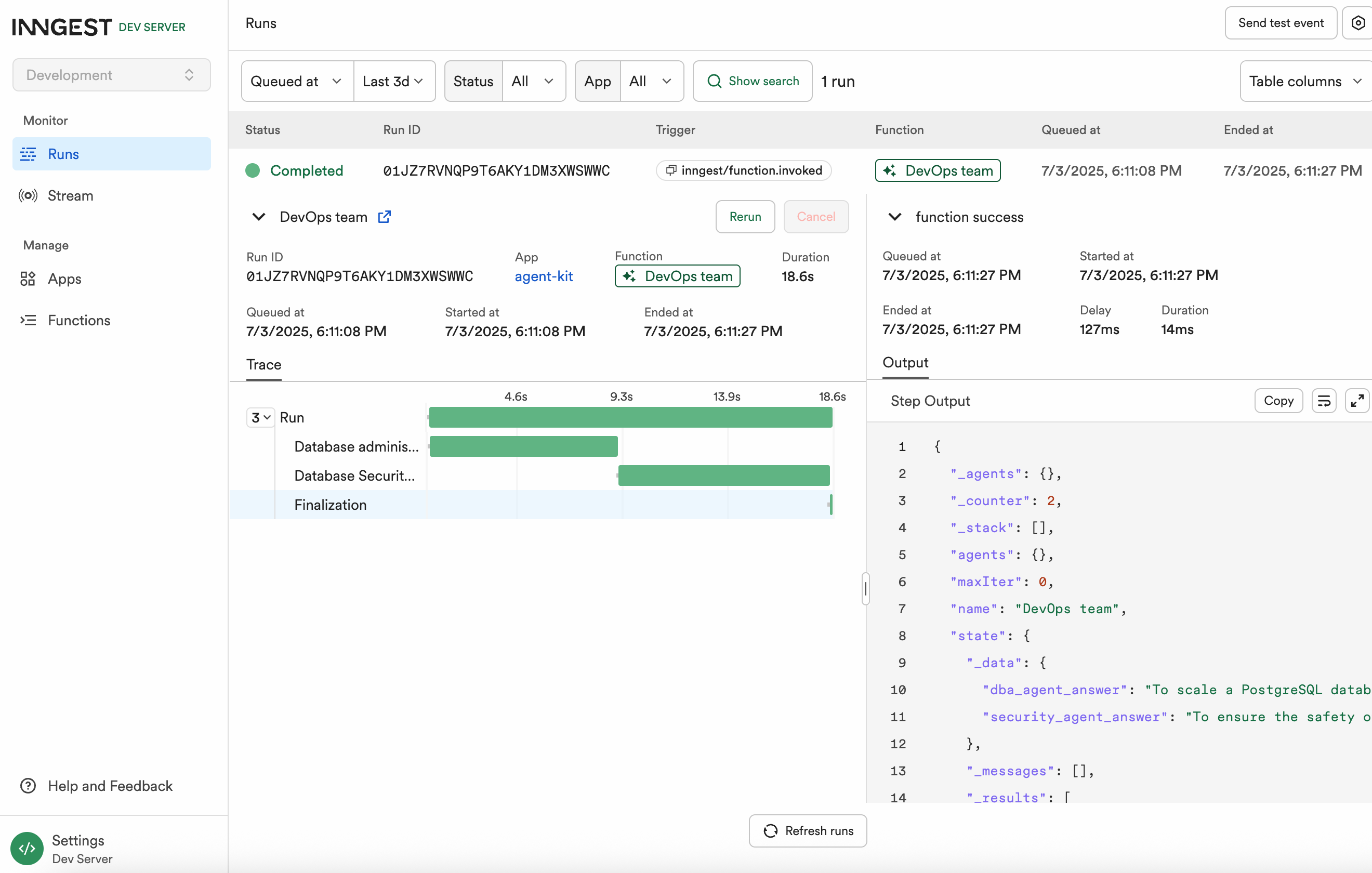
Output
{
"_agents": {},
"_counter": 2,
"_stack": [],
"agents": {},
"maxIter": 0,
"name": "DevOps team",
"state": {
"_data": {
"dba_agent_answer": "To scale a PostgreSQL database to handle millions of requests per second, consider the following strategies:\n\n1. Horizontal Scaling:\n- Use PostgreSQL partitioning for large tables\n- Implement read replicas for distributing read traffic\n- Consider sharding for distributing data across multiple servers\n\n2. Performance Optimization:\n- Create strategic indexes\n- Use connection pooling (PgBouncer)\n- Implement caching layers (Redis, PgMemento)\n- Use columnar storage extensions like cstore_fdw for analytical workloads\n\n3. Hardware and Configuration:\n- Use high-performance SSDs\n- Optimize PostgreSQL configuration (work_mem, shared_buffers)\n- Use powerful multi-core servers with high RAM\n- Consider cloud-native solutions like Amazon Aurora or CockroachDB\n\n4. Advanced Techniques:\n- Implement write-ahead logging (WAL) optimization\n- Use table partitioning for large datasets\n- Consider using TimescaleDB for time-series data\n- Implement asynchronous processing for non-critical tasks",
"security_agent_answer": "To ensure the safety of each organization's data in a multi-tenant Finance application, implement the following schema design strategies:\n\n1. Tenant Isolation:\n- Use a separate schema for each organization\n- Implement Row-Level Security (RLS)\n- Create a tenant_id column in all tables\n- Use PostgreSQL's native security policies\n\n2. Data Encryption:\n- Use column-level encryption for sensitive fields\n- Implement pgcrypto extension for secure encryption\n- Use SSL/TLS for all database connections\n- Enable data-at-rest encryption\n\n3. Access Control:\n- Create role-based access control (RBAC)\n- Use PostgreSQL's GRANT and REVOKE commands\n- Implement least privilege principle\n- Use separate database users for each application tier\n\n4. Audit and Compliance:\n- Enable PostgreSQL audit logging\n- Use triggers to track data modifications\n- Implement comprehensive logging of access and changes\n- Create an immutable audit trail\n\n5. Data Integrity:\n- Use constraints and foreign key relationships\n- Implement database-level validation rules\n- Use ACID transactions\n- Create comprehensive check constraints\n\n6. Secure Configuration:\n- Disable unnecessary PostgreSQL extensions\n- Use strong authentication methods\n- Implement connection limits\n- Regularly update and patch PostgreSQL\n\nExample Schema Structure:\n```sql\nCREATE SCHEMA organization_1;\nCREATE SCHEMA organization_2;\n\n-- Apply Row-Level Security\nALTER TABLE financial_records ENABLE ROW LEVEL SECURITY;\nCREATE POLICY tenant_isolation_policy ON financial_records\n FOR ALL USING (tenant_id = current_setting('app.current_tenant')::int);\n```\n\nThis approach ensures strict data separation, security, and compliance for multi-tenant financial applications."
},
"_messages": [],
"_results": [
{
"agentName": "Database administrator",
"createdAt": "2025-07-03T09:11:27.333Z",
"history": [],
"output": [
{
"content": "I'll help you address these important considerations for your Finance application using PostgreSQL best practices:\n\n1. Scaling to Millions of Requests per Second:",
"role": "assistant",
"stop_reason": "stop",
"type": "text"
},
{
"role": "assistant",
"stop_reason": "tool",
"tools": [
{
"id": "toolu_01JGDc5zkLwGQkUPiW2DG4YP",
"input": {
"answer": "To scale a PostgreSQL database to handle millions of requests per second, consider the following strategies:\n\n1. Horizontal Scaling:\n- Use PostgreSQL partitioning for large tables\n- Implement read replicas for distributing read traffic\n- Consider sharding for distributing data across multiple servers\n\n2. Performance Optimization:\n- Create strategic indexes\n- Use connection pooling (PgBouncer)\n- Implement caching layers (Redis, PgMemento)\n- Use columnar storage extensions like cstore_fdw for analytical workloads\n\n3. Hardware and Configuration:\n- Use high-performance SSDs\n- Optimize PostgreSQL configuration (work_mem, shared_buffers)\n- Use powerful multi-core servers with high RAM\n- Consider cloud-native solutions like Amazon Aurora or CockroachDB\n\n4. Advanced Techniques:\n- Implement write-ahead logging (WAL) optimization\n- Use table partitioning for large datasets\n- Consider using TimescaleDB for time-series data\n- Implement asynchronous processing for non-critical tasks"
},
"name": "provide_answer",
"type": "tool"
}
],
"type": "tool_call"
}
],
"prompt": [
{
"content": "You are a PostgreSQL expert database administrator. You only provide answers to questions linked to Postgres database schema, indexes, extensions.",
"role": "system",
"type": "text"
},
{
"content": "I am building a Finance application. Help me answer the following 2 questions: \n - How can I scale my application to millions of request per second? \n - How should I design my schema to ensure the safety of each organization's data?",
"role": "user",
"type": "text"
}
],
"raw": "{\"content\":[{\"text\":\"I'll help you address these important considerations for your Finance application using PostgreSQL best practices:\\n\\n1. Scaling to Millions of Requests per Second:\",\"type\":\"text\"},{\"id\":\"toolu_01JGDc5zkLwGQkUPiW2DG4YP\",\"input\":{\"answer\":\"To scale a PostgreSQL database to handle millions of requests per second, consider the following strategies:\\n\\n1. Horizontal Scaling:\\n- Use PostgreSQL partitioning for large tables\\n- Implement read replicas for distributing read traffic\\n- Consider sharding for distributing data across multiple servers\\n\\n2. Performance Optimization:\\n- Create strategic indexes\\n- Use connection pooling (PgBouncer)\\n- Implement caching layers (Redis, PgMemento)\\n- Use columnar storage extensions like cstore_fdw for analytical workloads\\n\\n3. Hardware and Configuration:\\n- Use high-performance SSDs\\n- Optimize PostgreSQL configuration (work_mem, shared_buffers)\\n- Use powerful multi-core servers with high RAM\\n- Consider cloud-native solutions like Amazon Aurora or CockroachDB\\n\\n4. Advanced Techniques:\\n- Implement write-ahead logging (WAL) optimization\\n- Use table partitioning for large datasets\\n- Consider using TimescaleDB for time-series data\\n- Implement asynchronous processing for non-critical tasks\"},\"name\":\"provide_answer\",\"type\":\"tool_use\"}],\"id\":\"msg_01MyvqoabwrgmRca9dZB6oRw\",\"model\":\"claude-3-5-haiku-20241022\",\"role\":\"assistant\",\"stop_reason\":\"tool_use\",\"stop_sequence\":null,\"type\":\"message\",\"usage\":{\"cache_creation_input_tokens\":0,\"cache_read_input_tokens\":0,\"input_tokens\":434,\"output_tokens\":320,\"service_tier\":\"standard\"}}",
"toolCalls": [
{
"content": {
"data": "provide_answer successfully executed"
},
"role": "tool_result",
"stop_reason": "tool",
"tool": {
"id": "toolu_01JGDc5zkLwGQkUPiW2DG4YP",
"name": "provide_answer",
"type": "tool"
},
"type": "tool_result"
}
]
},
{
"agentName": "Database Security Expert",
"createdAt": "2025-07-03T09:11:27.335Z",
"history": [
{
"content": "I'll help you address these important considerations for your Finance application using PostgreSQL best practices:\n\n1. Scaling to Millions of Requests per Second:",
"role": "assistant",
"stop_reason": "stop",
"type": "text"
},
{
"role": "assistant",
"stop_reason": "tool",
"tools": [
{
"id": "toolu_01JGDc5zkLwGQkUPiW2DG4YP",
"input": {
"answer": "To scale a PostgreSQL database to handle millions of requests per second, consider the following strategies:\n\n1. Horizontal Scaling:\n- Use PostgreSQL partitioning for large tables\n- Implement read replicas for distributing read traffic\n- Consider sharding for distributing data across multiple servers\n\n2. Performance Optimization:\n- Create strategic indexes\n- Use connection pooling (PgBouncer)\n- Implement caching layers (Redis, PgMemento)\n- Use columnar storage extensions like cstore_fdw for analytical workloads\n\n3. Hardware and Configuration:\n- Use high-performance SSDs\n- Optimize PostgreSQL configuration (work_mem, shared_buffers)\n- Use powerful multi-core servers with high RAM\n- Consider cloud-native solutions like Amazon Aurora or CockroachDB\n\n4. Advanced Techniques:\n- Implement write-ahead logging (WAL) optimization\n- Use table partitioning for large datasets\n- Consider using TimescaleDB for time-series data\n- Implement asynchronous processing for non-critical tasks"
},
"name": "provide_answer",
"type": "tool"
}
],
"type": "tool_call"
},
{
"content": {
"data": "provide_answer successfully executed"
},
"role": "tool_result",
"stop_reason": "tool",
"tool": {
"id": "toolu_01JGDc5zkLwGQkUPiW2DG4YP",
"name": "provide_answer",
"type": "tool"
},
"type": "tool_result"
}
],
"output": [
{
"content": "2. Schema Design for Data Safety:",
"role": "assistant",
"stop_reason": "stop",
"type": "text"
},
{
"role": "assistant",
"stop_reason": "tool",
"tools": [
{
"id": "toolu_01BuLdGvsto4NaSonwagmLUE",
"input": {
"answer": "To ensure the safety of each organization's data in a multi-tenant Finance application, implement the following schema design strategies:\n\n1. Tenant Isolation:\n- Use a separate schema for each organization\n- Implement Row-Level Security (RLS)\n- Create a tenant_id column in all tables\n- Use PostgreSQL's native security policies\n\n2. Data Encryption:\n- Use column-level encryption for sensitive fields\n- Implement pgcrypto extension for secure encryption\n- Use SSL/TLS for all database connections\n- Enable data-at-rest encryption\n\n3. Access Control:\n- Create role-based access control (RBAC)\n- Use PostgreSQL's GRANT and REVOKE commands\n- Implement least privilege principle\n- Use separate database users for each application tier\n\n4. Audit and Compliance:\n- Enable PostgreSQL audit logging\n- Use triggers to track data modifications\n- Implement comprehensive logging of access and changes\n- Create an immutable audit trail\n\n5. Data Integrity:\n- Use constraints and foreign key relationships\n- Implement database-level validation rules\n- Use ACID transactions\n- Create comprehensive check constraints\n\n6. Secure Configuration:\n- Disable unnecessary PostgreSQL extensions\n- Use strong authentication methods\n- Implement connection limits\n- Regularly update and patch PostgreSQL\n\nExample Schema Structure:\n```sql\nCREATE SCHEMA organization_1;\nCREATE SCHEMA organization_2;\n\n-- Apply Row-Level Security\nALTER TABLE financial_records ENABLE ROW LEVEL SECURITY;\nCREATE POLICY tenant_isolation_policy ON financial_records\n FOR ALL USING (tenant_id = current_setting('app.current_tenant')::int);\n```\n\nThis approach ensures strict data separation, security, and compliance for multi-tenant financial applications."
},
"name": "provide_answer",
"type": "tool"
}
],
"type": "tool_call"
}
],
"prompt": [
{
"content": "You are a PostgreSQL security expert. Provide answers to questions linked to PostgreSQL security topics such as encryption, access control, audit logging, and compliance best practices.",
"role": "system",
"type": "text"
},
{
"content": "I am building a Finance application. Help me answer the following 2 questions: \n - How can I scale my application to millions of request per second? \n - How should I design my schema to ensure the safety of each organization's data?",
"role": "user",
"type": "text"
}
],
"raw": "{\"content\":[{\"text\":\"2. Schema Design for Data Safety:\",\"type\":\"text\"},{\"id\":\"toolu_01BuLdGvsto4NaSonwagmLUE\",\"input\":{\"answer\":\"To ensure the safety of each organization's data in a multi-tenant Finance application, implement the following schema design strategies:\\n\\n1. Tenant Isolation:\\n- Use a separate schema for each organization\\n- Implement Row-Level Security (RLS)\\n- Create a tenant_id column in all tables\\n- Use PostgreSQL's native security policies\\n\\n2. Data Encryption:\\n- Use column-level encryption for sensitive fields\\n- Implement pgcrypto extension for secure encryption\\n- Use SSL/TLS for all database connections\\n- Enable data-at-rest encryption\\n\\n3. Access Control:\\n- Create role-based access control (RBAC)\\n- Use PostgreSQL's GRANT and REVOKE commands\\n- Implement least privilege principle\\n- Use separate database users for each application tier\\n\\n4. Audit and Compliance:\\n- Enable PostgreSQL audit logging\\n- Use triggers to track data modifications\\n- Implement comprehensive logging of access and changes\\n- Create an immutable audit trail\\n\\n5. Data Integrity:\\n- Use constraints and foreign key relationships\\n- Implement database-level validation rules\\n- Use ACID transactions\\n- Create comprehensive check constraints\\n\\n6. Secure Configuration:\\n- Disable unnecessary PostgreSQL extensions\\n- Use strong authentication methods\\n- Implement connection limits\\n- Regularly update and patch PostgreSQL\\n\\nExample Schema Structure:\\n```sql\\nCREATE SCHEMA organization_1;\\nCREATE SCHEMA organization_2;\\n\\n-- Apply Row-Level Security\\nALTER TABLE financial_records ENABLE ROW LEVEL SECURITY;\\nCREATE POLICY tenant_isolation_policy ON financial_records\\n FOR ALL USING (tenant_id = current_setting('app.current_tenant')::int);\\n```\\n\\nThis approach ensures strict data separation, security, and compliance for multi-tenant financial applications.\"},\"name\":\"provide_answer\",\"type\":\"tool_use\"}],\"id\":\"msg_013zM33azkcwKsTNp4KPeFLJ\",\"model\":\"claude-3-5-haiku-20241022\",\"role\":\"assistant\",\"stop_reason\":\"tool_use\",\"stop_sequence\":null,\"type\":\"message\",\"usage\":{\"cache_creation_input_tokens\":0,\"cache_read_input_tokens\":0,\"input_tokens\":782,\"output_tokens\":450,\"service_tier\":\"standard\"}}",
"toolCalls": [
{
"content": {
"data": "provide_answer successfully executed"
},
"role": "tool_result",
"stop_reason": "tool",
"tool": {
"id": "toolu_01BuLdGvsto4NaSonwagmLUE",
"name": "provide_answer",
"type": "tool"
},
"type": "tool_result"
}
]
}
],
"data": {
"dba_agent_answer": "To scale a PostgreSQL database to handle millions of requests per second, consider the following strategies:\n\n1. Horizontal Scaling:\n- Use PostgreSQL partitioning for large tables\n- Implement read replicas for distributing read traffic\n- Consider sharding for distributing data across multiple servers\n\n2. Performance Optimization:\n- Create strategic indexes\n- Use connection pooling (PgBouncer)\n- Implement caching layers (Redis, PgMemento)\n- Use columnar storage extensions like cstore_fdw for analytical workloads\n\n3. Hardware and Configuration:\n- Use high-performance SSDs\n- Optimize PostgreSQL configuration (work_mem, shared_buffers)\n- Use powerful multi-core servers with high RAM\n- Consider cloud-native solutions like Amazon Aurora or CockroachDB\n\n4. Advanced Techniques:\n- Implement write-ahead logging (WAL) optimization\n- Use table partitioning for large datasets\n- Consider using TimescaleDB for time-series data\n- Implement asynchronous processing for non-critical tasks",
"security_agent_answer": "To ensure the safety of each organization's data in a multi-tenant Finance application, implement the following schema design strategies:\n\n1. Tenant Isolation:\n- Use a separate schema for each organization\n- Implement Row-Level Security (RLS)\n- Create a tenant_id column in all tables\n- Use PostgreSQL's native security policies\n\n2. Data Encryption:\n- Use column-level encryption for sensitive fields\n- Implement pgcrypto extension for secure encryption\n- Use SSL/TLS for all database connections\n- Enable data-at-rest encryption\n\n3. Access Control:\n- Create role-based access control (RBAC)\n- Use PostgreSQL's GRANT and REVOKE commands\n- Implement least privilege principle\n- Use separate database users for each application tier\n\n4. Audit and Compliance:\n- Enable PostgreSQL audit logging\n- Use triggers to track data modifications\n- Implement comprehensive logging of access and changes\n- Create an immutable audit trail\n\n5. Data Integrity:\n- Use constraints and foreign key relationships\n- Implement database-level validation rules\n- Use ACID transactions\n- Create comprehensive check constraints\n\n6. Secure Configuration:\n- Disable unnecessary PostgreSQL extensions\n- Use strong authentication methods\n- Implement connection limits\n- Regularly update and patch PostgreSQL\n\nExample Schema Structure:\n```sql\nCREATE SCHEMA organization_1;\nCREATE SCHEMA organization_2;\n\n-- Apply Row-Level Security\nALTER TABLE financial_records ENABLE ROW LEVEL SECURITY;\nCREATE POLICY tenant_isolation_policy ON financial_records\n FOR ALL USING (tenant_id = current_setting('app.current_tenant')::int);\n```\n\nThis approach ensures strict data separation, security, and compliance for multi-tenant financial applications."
},
"kv": {}
}
}エージェントのAnswer
**DBA Agent の回答**
To scale a PostgreSQL database to handle millions of requests per second,
consider the following strategies:
1. Horizontal Scaling:
* Use PostgreSQL partitioning for large tables
* Implement read replicas for distributing read traffic
* Consider sharding for distributing data across multiple servers
2. Performance Optimization:
* Create strategic indexes
* Use connection pooling (PgBouncer)
* Implement caching layers (Redis, PgMemento)
* Use columnar storage extensions like cstore\_fdw for analytical
workloads
3. Hardware and Configuration:
* Use high-performance SSDs
* Optimize PostgreSQL configuration (work\_mem, shared\_buffers)
* Use powerful multi-core servers with high RAM
* Consider cloud-native solutions like Amazon Aurora or CockroachDB
4. Advanced Techniques:
* Implement write-ahead logging (WAL) optimization
* Use table partitioning for large datasets
* Consider using TimescaleDB for time-series data
* Implement asynchronous processing for non-critical tasks
---
**Security Agent の回答**
To ensure the safety of each organization’s data in a multi-tenant finance
application, implement the following schema design strategies:
1. Tenant Isolation:
* Use a separate schema for each organization
* Implement Row-Level Security (RLS)
* Create a tenant\_id column in all tables
* Use PostgreSQL’s native security policies
2. Data Encryption:
* Use column-level encryption for sensitive fields
* Implement pgcrypto extension for secure encryption
* Use SSL/TLS for all database connections
* Enable data-at-rest encryption
3. Access Control:
* Create role-based access control (RBAC)
* Use PostgreSQL’s GRANT and REVOKE commands
* Implement least-privilege principle
* Use separate database users for each application tier
4. Audit and Compliance:
* Enable PostgreSQL audit logging
* Use triggers to track data modifications
* Implement comprehensive logging of access and changes
* Create an immutable audit trail
5. Data Integrity:
* Use constraints and foreign key relationships
* Implement database-level validation rules
* Use ACID transactions
* Create comprehensive check constraints
6. Secure Configuration:
* Disable unnecessary PostgreSQL extensions
* Use strong authentication methods
* Implement connection limits
* Regularly update and patch PostgreSQL
**Example Schema Structure**
```sql
CREATE SCHEMA organization_1;
CREATE SCHEMA organization_2;
-- Apply Row-Level Security
ALTER TABLE financial_records ENABLE ROW LEVEL SECURITY;
CREATE POLICY tenant_isolation_policy
ON financial_records
FOR ALL USING (tenant_id = current_setting('app.current_tenant')::int);
```