


Firestoreとは?
Cloud Firestoreは、FirebaseとGoogle Cloudが提供する柔軟でスケーラブルなNoSQLドキュメントデータベースです。Web、モバイル、サーバー開発向けに設計されており、リアルタイム同期とオフラインサポートが特徴です。
主なコンセプトは以下の通りです。
- ドキュメントとコレクション : Firestoreのデータは「ドキュメント」として保存されます。ドキュメントはキーと値のペアで構成されるデータの集合です。これらのドキュメントは「コレクション」にまとめられます。コレクションはドキュメントの集まりであり、さらにその中にサブコレクションとして別のコレクションを含めることもできます。これにより、データを階層的に整理できます。
- データ操作 :
- 追加 (Add/Set) : コレクションに新しいドキュメントを追加したり、特定のIDでドキュメントを保存したりします。
- 読み取り (Get) : ドキュメントのIDを指定してデータを取得したり、コレクションから複数のドキュメントをクエリ(検索)して取得したりします。
- 更新 (Update) : 既存のドキュメントの特定フィールドを更新します。
- 削除 (Delete) : ドキュメント全体や、ドキュメント内の特定のフィールドを削除します。
- リアルタイム同期 : Firestoreの最大の魅力の一つは、データの変更をリアルタイムでクライアントに同期する機能です。データベースのデータが更新されると、接続されているすべてのクライアント(あなたのWebアプリなど)に自動的に反映されます。
TypeScriptやJavaScriptのWebアプリでは、Firebase SDKを使ってこれらの操作を行います。初期設定後、 firestore().collection('yourCollection').doc('yourDocument').get() のようにチェーンメソッドで簡単にデータにアクセスできます。
Firestoreを使うことで、バックエンドを気にすることなく、データの保存、同期、クエリといった機能をあなたのWebアプリに素早く組み込むことができます。
サンプルDBを作って試す
Cloud Firestoreデータベースを作成する手順
Firebase コンソールを開く : Firebase コンソールにアクセスし、左側のメニューから「 Firestore Database 」を選択し、データベースの作成をクリックします。
エディションの選択:Standard, EnterpriseからStandardを選択
ロケーションの選択:asia-northeast1 (Tokyo)を選択
構成:本番モード、テストモードがあり、テストモードを選択
コレクションを作成
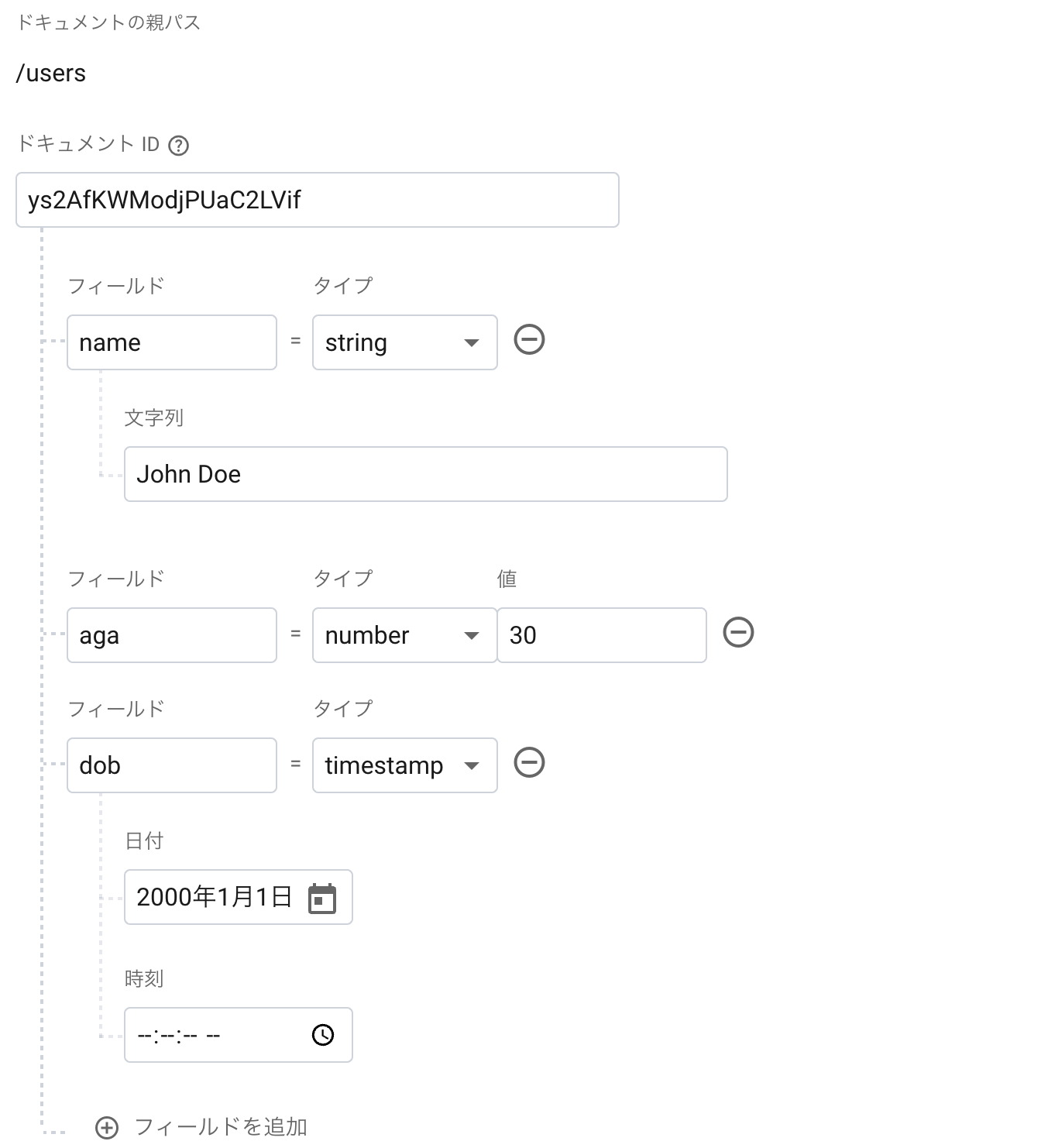
コレクション名:users
ドキュメント:
- ID 自動生成
- name: String “John Doe”
- age: Number: 30
- dob: timestamp 2000-01-01
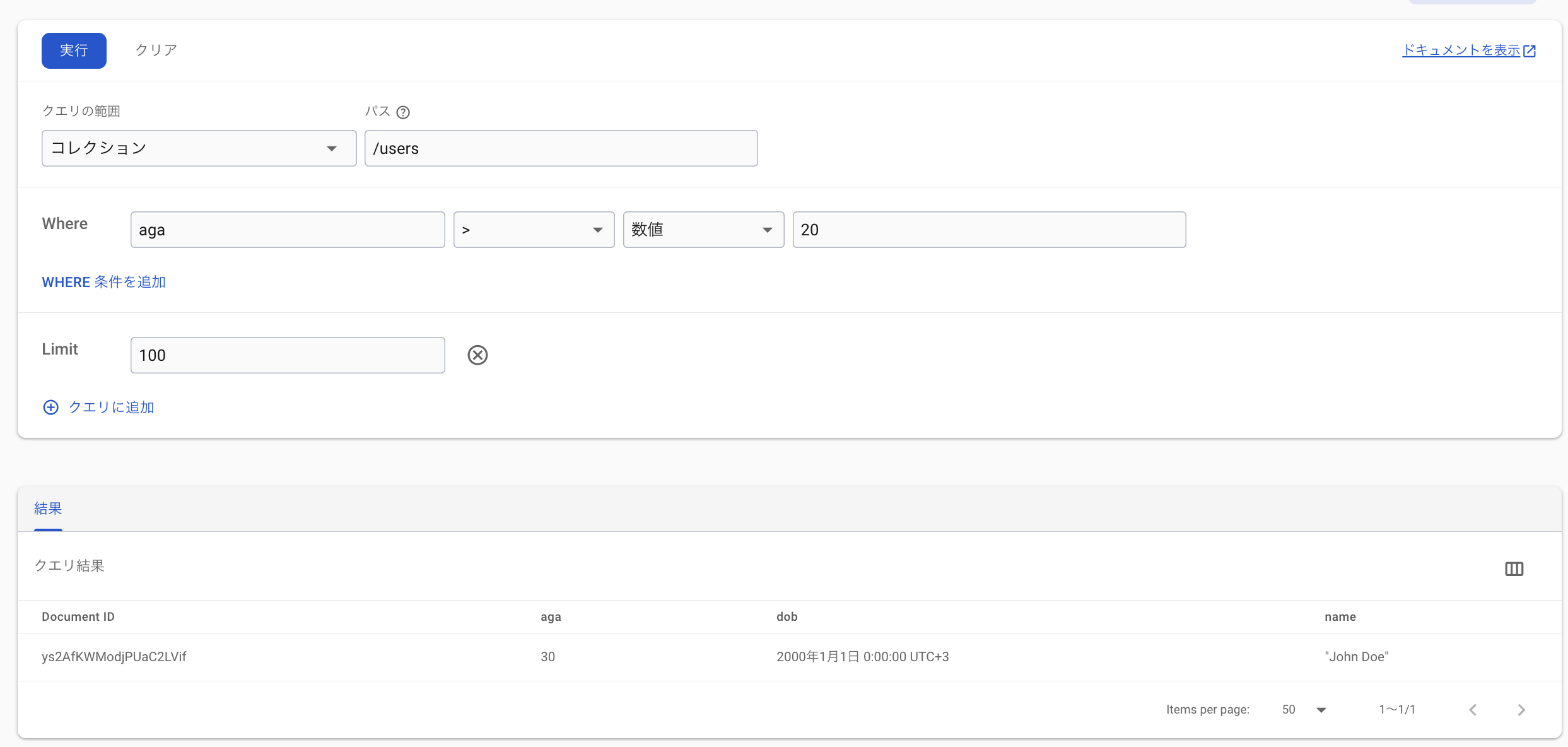
クエリを実行する
Firestoreの特徴
ドキュメント名
Firestoreのデータは、常に コレクション と ドキュメント が交互に現れる厳密な階層構造で構成されます。
- コレクション(Collection) :
- ドキュメントの集まりを意味します。例えるなら、ファイルの「フォルダ」のような存在ですが、単なる容器ではありません。
- コレクション自体がデータの検索(クエリ)の対象となります。例えば、
usersコレクションからすべてのユーザーデータを取得したり、条件に合うユーザーを探したりできます。
- ドキュメント(Document) :
- コレクション内に格納される、データの実体です。JSONオブジェクトのようにキーと値のペアで構成される、柔軟なデータ形式を持っています。
- 各ドキュメントは、そのコレクション内で一意なID(ドキュメント名)を持ちます。このIDはFirestoreが自動生成することも、開発者が自分で指定することも可能です。
この構造により、Firestoreのドキュメントパスは常に コレクション/ドキュメント/コレクション/ドキュメント/... というパターンになります。
例えば、 users/alovelace/ai_threads/thread123/messages/message_abc というパスは、以下の階層を示しています。
users: コレクション(ユーザーの集まり)alovelace: ドキュメント(特定のユーザー)ai_threads: サブコレクション(特定のユーザーのAI会話スレッドの集まり)thread123: ドキュメント(特定のAI会話スレッド)messages: サブコレクション(特定のAI会話スレッドのメッセージの集まり)message_abc: ドキュメント(特定のメッセージ)
この階層構造は、データ設計において非常に重要です。
- データモデリング : 関連性の高いデータをサブコレクションにまとめることで、自然で整理されたデータ構造を構築できます。
- クエリの最適化 : 特定のパス(コレクション)に絞って効率的なクエリを実行できます。
- セキュリティルール : このパスの各セグメントを利用して、きめ細やかなアクセス制御を実装できます。「どのユーザーが、どのコレクション内の、どのドキュメントを読み書きできるか」といったルールを柔軟に定義可能です。
複数のドキュメントをJOINできない
Firestoreでは、関連するデータを扱うために主に以下のいずれかのアプローチを取ります。
- デノーマライズ(データ重複) :
- 最も一般的なFirestoreの設計パターンです。頻繁に一緒に使われる関連データの一部を、参照元と参照先の両方のドキュメントに重複して格納します。
- 例 : 「投稿」ドキュメントに「ユーザーID」だけでなく「ユーザー名」も一緒に保存する。
- 利点 : データの取得が1回のクエリで済み、高速です。JOINのような複雑な処理が不要。
- 欠点 : データが重複するため、元データが変更された際に、重複している全ての箇所を更新する(整合性を保つ)ためのロジック(通常はCloud Functionsで実装)が必要になります。
- サブコレクション :
- 親ドキュメントに直接関連する「多」のデータがある場合に利用します。
- 例 :
users/{userId}/posts/{postId}や、ai_threads/{threadId}/messages/{messageId}のように、ユーザーの下に投稿、スレッドの下にメッセージを格納する。 - 利点 : データの階層が明確になり、親データと子データが論理的に結びつきます。子データは独立したドキュメントとして管理されるため、1MBのサイズ制限問題もクリアしやすいです。
- 欠点 : 親ドキュメントを取得しても子ドキュメントは取得されません。親と子を同時に取得するには、2回のクエリ(親ドキュメントとサブコレクションのクエリ)が必要です。
- 複数回のクエリ(クライアントサイド/サーバーサイドでの「擬似JOIN」) :
- データが重複を許容できない場合や、関係性が複雑な場合に利用します。まず一つのコレクションからドキュメントを取得し、そのドキュメントに含まれるID(参照)を使って、別のコレクションから関連ドキュメントを個別に取得します。
- 例 : 「投稿」ドキュメントから「ユーザーID」を取得し、そのIDを使って「ユーザー」コレクションからユーザー情報を別途取得する。
- 利点 : データが重複しないため、整合性ロジックが不要です。
- 欠点 : 複数回のネットワークラウンドトリップが発生するため、デノーマライズに比べて遅くなる可能性があります。
1MB制限
Firestoreの「1MBのドキュメントサイズ制限」は、Firestoreでデータモデリングを考える上で非常に重要な制約です。これは、 1つのドキュメントに保存できるデータの総量が最大1メガバイト であることを意味します。
1MB制限とは何か
この1MBには、ドキュメントの実際のデータだけでなく、フィールド名、値、ドキュメントのインデックスエントリ、そしてFirestoreが内部的に使用するメタデータなども含まれます。純粋なテキストだけで換算するとかなりの量になりますが(数万~数十万文字程度)、画像データなどをBase64エンコードして直接埋め込もうとすると、あっという間に制限に達してしまいます。
なぜ1MBの制限があるのか?
この制限は、Firestoreが 高いパフォーマンス、リアルタイム性、そして大規模な自動スケーリング を世界規模で提供するために、意図的に設けられています。
- 高速な読み書き : 小さなドキュメントは、データベースサーバーがメモリにロードしたり、ネットワーク越しにクライアントに送ったりする際に非常に効率的です。これにより、Firestoreの最大の売りであるリアルタイム同期がスムーズに行われます。
- 効率的なスケーリング : ドキュメントが小さく保たれることで、データを分散して保存・処理する際の複雑さが軽減され、水平スケーリングが容易になります。
- メモリとインデックスの効率化 : 各ドキュメントに対してインデックスが作成されるため、ドキュメントサイズが小さいほど、インデックスの管理や検索が効率的になります。
対応方法
- サブコレクションの活用 :
- 関連する多くのアイテムや、成長するリスト(例: AIとの会話履歴の各メッセージ)がある場合、それらを 親ドキュメントのサブコレクションとして独立したドキュメント として保存します。これにより、親ドキュメントの1MB制限とは別に、各子ドキュメントがそれぞれ1MBの制限を持つことになります。
- Cloud Storage for Firebaseとの併用 :
- 画像、動画、音声、非常に長いテキストファイルなど、バイナリデータや確実に1MBを超える大きなコンテンツは、Firestoreドキュメントに直接保存せず、 Cloud Storage for Firebase に保存します。Firestoreドキュメントには、そのファイルのURLやパスだけを保存するようにします。
- 必要な情報のみを保存 :
- ドキュメントには、アプリケーションにとって本当に必要なデータだけを保存し、不必要な重複や冗長な情報を避けるようにします。
Firestoreの1MB制限は、その設計思想を理解し、サブコレクションやCloud Storageを効果的に利用することで、堅牢で高性能なアプリケーションを構築するための強力な指針となります。
Firestoreのインデックス
インデックスの対象
- ドキュメント内のフィールドにはインデックスを貼れる
- ドキュメント ID には擬似フィールド
__name__経由でインデックスを貼れる - コレクション名はインデックスに使えない
クエリー例
- documentsコレクション内のドキュメントでkeyがマッチして、created_atが1時間1以内のデータを抽出
- インデックスが存在しない場合、クエリーは失敗し、インデックスをつくるためのurlがエラーログ内に記載された
{
"structuredQuery": {
"from": [
{
"collectionId": "documents"
}
],
"where": {
"compositeFilter": {
"op": "AND",
"filters": [
{
"fieldFilter": {
"field": { "fieldPath": "key" },
"op": "EQUAL",
"value": {
"stringValue": "{{ $json.key }}"
}
}
},
{
"fieldFilter": {
"field": { "fieldPath": "created_at" },
"op": "GREATER_THAN_OR_EQUAL",
"value": {
"timestampValue": "{{ new Date(Date.now() - 1*60*60*1000).toISOString() }}"
}
}
}
]
}
}
}
}